« IA et cybersécurité » : différence entre les versions
Aucun résumé des modifications |
Aucun résumé des modifications |
||
| Ligne 3 : | Ligne 3 : | ||
|ImageStr=MicrosoftTeams-image (2).png | |ImageStr=MicrosoftTeams-image (2).png | ||
|StartDate=2021/05/05 | |StartDate=2021/05/05 | ||
|EndDate= | |EndDate=2023/12/31 | ||
|Cycle=Cycle 2 | |Cycle=Cycle 2 | ||
|Status=En cours | |Status=En cours | ||
| Ligne 20 : | Ligne 20 : | ||
=== Livrables souhaités === | === Livrables souhaités === | ||
# Livre blanc de synthèse sur des cas d’usage IA pour la cybersécurité | |||
# Sandbox IA pour la cybersécurité : Plateforme IA avec outils et data sets | |||
# Parcours de formations à l’IA pour les professionnels de la cyber | |||
# Cartographie des startups IA | |||
# Livre blanc sur les menaces spécifiques de l’IA | |||
== Synthèse des activités du GT == | == Synthèse des activités du GT == | ||
| Ligne 30 : | Ligne 30 : | ||
=== Quels acteurs impliqués dans les projets d'intelligence artificielle ? === | === Quels acteurs impliqués dans les projets d'intelligence artificielle ? === | ||
Les projets d’Intelligence Artificielle impliquent de nombreux acteurs afin de valoriser la donnée et de répondre au cas d’usages préalablement identifié. L’identification des ressources clés est un enjeu majeur pour tout expert en cybersécurité au démarrage d’un projet, une description succincte des rôles et responsabilité permet d’identifier rapidement les parties prenantes. Les différentes phases d’un projet IA, dont le développement, la mise en production et le suivi d’une application IA fait appel à de nombreux acteurs, dont certains sont spécialistes de data science et d’autres ne le sont pas. Le schéma ci-dessous présente les quatre grandes familles d’acteurs identifiés : | Les projets d’Intelligence Artificielle impliquent de nombreux acteurs afin de valoriser la donnée et de répondre au cas d’usages préalablement identifié. L’identification des ressources clés est un enjeu majeur pour tout expert en cybersécurité au démarrage d’un projet, une description succincte des rôles et responsabilité permet d’identifier rapidement les parties prenantes. Les différentes phases d’un projet IA, dont le développement, la mise en production et le suivi d’une application IA fait appel à de nombreux acteurs, dont certains sont spécialistes de data science et d’autres ne le sont pas. Le schéma ci-dessous présente les quatre grandes familles d’acteurs identifiés : | ||
# Les profils « métier », en charge du cas d’usage et de la validation de celui-ci par rapport aux objectifs de l’entreprise ; | |||
# Les spécialistes de data science, en charge de la mise en œuvre des techniques d’Intelligence Artificielle pour répondre aux besoins identifiés par les « métier » ; | |||
# Les profils IT, en charge du développement et de la mise en production des cas d’usages conçus par les spécialistes de la data science ; | |||
# Les profils « risque », en charge du contrôle et du respect des pratiques mises en œuvre par rapport aux politiques internes et réglementations externes. | |||
Notons que chaque entreprise peut avoir des noms un peu différents pour ces profils, voire découper différemment les rôles sur différents acteurs. Les descriptions suivantes sont donc à adapter à chaque cas : | Notons que chaque entreprise peut avoir des noms un peu différents pour ces profils, voire découper différemment les rôles sur différents acteurs. Les descriptions suivantes sont donc à adapter à chaque cas : | ||
A mettre sous format graphique | A mettre sous format graphique | ||
# '''Profils « métier » ''' | |||
:: | :: Sponsor métier : l’entité ou la personne qui émet une expression de besoin pour un nouveau projet et qui est responsable de l’évaluation métier du projet en production. | ||
:: | :: Citizen data scientist : il peut exécuter des processus de production de modèles avec des outils simples (no-code) pour démontrer/ explorer la valeur métier | ||
:: | :: Analyste métier : il analyse les besoins métier et identifie les indicateurs de performance métier (KPI) | ||
:: | :: Chef de projet IA : Il accompagne le projet dans l’expression fonctionnelle des besoins et pilote leur traduction en réalisation technique et leur exécution. Il encadre l’équipe projet. | ||
# '''Spécialistes de data science''' | |||
:: | :: Data analyst : Il réalise des études autour des données, et en restitue les conclusions | ||
:: | :: Data engineer : il analyse les besoins en données, il définit les processus de collecte et monitoring selon les modes d’interaction (batch, fil de l’eau) | ||
:: | :: Data scientist : c’est l’expert en data science, il conçoit le pipeline de construction du modèle et produit / sélectionne le modèle | ||
::- Data visualizer : il élabore des visualisations des données et des résultats à destination des data scientists et des spécialistes métier | ::- Data visualizer : il élabore des visualisations des données et des résultats à destination des data scientists et des spécialistes métier | ||
:: | :: Validateur de modèle : il s’assure de la validité du modèle et évalue ses conséquences non désirées éventuelles. Il assure une revue du modèle indépendante du développeur (data scientist) | ||
# '''Profils IT''' | |||
:: | :: Architecte solution : il propose une architecture de solution, comprenant les contraintes de cybersécurité | ||
:: | :: Administrateur plateforme de production : il est responsable de la plateforme informatique où s’exécutent les modèles. Il assure le traitement des alertes et les reprises sur incidents lors des phases d’apprentissage et d’inférence | ||
:: | :: Machine learning engineer : il intègre les pipelines machine learning dans des processus Machine Learning Operations(MLOps) | ||
:: | :: Architecte de données : il conçoit les infrastructures et les solutions Data, il identifie les différentes sources de données | ||
:: | :: Data manager : Il assure l’organisation et la gestion des données sur son domaine de responsabilité. Il agit comme un référent pour les données. | ||
# '''Profils risque''' | |||
:: | :: IA Security Champion : il apporte la déclinaison des politiques de sécurité pour le système IA | ||
:: | :: Délégué à la Protection des Données (DPD) : il veille au respect de la réglementation sur la protection des données personnelle | ||
:: | :: Responsable de la Sécurité des Systèmes d'Information (RSSI) : il décline les enjeux et besoins de sécurité pour le système IA. Il valide les niveaux de risques associés au système | ||
Certains de ces profils sont transverses et interviennent sur de nombreux projets (sponsor métier, administrateur de plateforme de production, architecte données et profils risque) alors que d’autres sont dédiés à un projet et constituent une équipe projet. Les profils risque doivent donc intervenir aux côtés de profils IA dans des équipes projet mixtes. | Certains de ces profils sont transverses et interviennent sur de nombreux projets (sponsor métier, administrateur de plateforme de production, architecte données et profils risque) alors que d’autres sont dédiés à un projet et constituent une équipe projet. Les profils risque doivent donc intervenir aux côtés de profils IA dans des équipes projet mixtes. | ||
| Ligne 63 : | Ligne 63 : | ||
=== Quels apports de l'intelligence artificielle pour la cybersécurité ? === | === Quels apports de l'intelligence artificielle pour la cybersécurité ? === | ||
L’Intelligence Artificielle, en tant que domaine scientifique, bénéficie de nombreuses avancées sur les dernières années, notamment grâce à la mise en commun de techniques, capacités et données permettant l’utilisation des approches statistiques du Machine Learning au détriment des approches déterministes des Systèmes Experts. Cette approche permet une généralisation et apporte des bénéfices lorsqu’un nombre significatif de données est mis en commun pour limiter les effets statistiques. De fait, les domaines de recherches en cybersécurité sont naturellement portés autours des axes suivants : | L’Intelligence Artificielle, en tant que domaine scientifique, bénéficie de nombreuses avancées sur les dernières années, notamment grâce à la mise en commun de techniques, capacités et données permettant l’utilisation des approches statistiques du Machine Learning au détriment des approches déterministes des Systèmes Experts. Cette approche permet une généralisation et apporte des bénéfices lorsqu’un nombre significatif de données est mis en commun pour limiter les effets statistiques. De fait, les domaines de recherches en cybersécurité sont naturellement portés autours des axes suivants : | ||
# '''L’identification et la localisation des informations de l’entreprise,''' en commençant pas la classification de ces informations, et l’application de politiques dynamiques ; | |||
# '''La protection par l’analyse de signaux faibles et des comportements usuels,''' les systèmes à bas d’IA permettent de configurer les politiques et mécanismes de sécurité le plus efficacement possible ; | |||
# '''La détection en analysant la moindre variation des comportements et des changements réalisés sur les infrastructures''' afin de construire dynamiquement les scénarios de détection ; | |||
# '''La reprise via l’aide à la prise de décision,''' en ayant une connaissance fine du système d’information, permet d’établir la stratégie de réponse et de reprise associé à un incident de cybersécurité. | |||
| Ligne 72 : | Ligne 72 : | ||
Ce Framework de classification des cas d’usages est une initiative du Groupe de Travail : il est basé sur les guides et standards du domaine et se veut « pratique » pour catégoriser simplement des cas d’usages et favoriser l’identification de nouveaux cas. En complément de l’aide à l’organisation des connaissances, ce framework a été conçu pour faciliter le partage avec des entités internationales. Il est construit autour de trois axes : | Ce Framework de classification des cas d’usages est une initiative du Groupe de Travail : il est basé sur les guides et standards du domaine et se veut « pratique » pour catégoriser simplement des cas d’usages et favoriser l’identification de nouveaux cas. En complément de l’aide à l’organisation des connaissances, ce framework a été conçu pour faciliter le partage avec des entités internationales. Il est construit autour de trois axes : | ||
[[Fichier:Framework.png|vignette|439x439px]] | [[Fichier:Framework.png|vignette|439x439px]] | ||
#la catégorisation des cas d'usages suivant les activités des équipes cybersécurité, en suivant un découpage typique d'une organisation cybersécurité; | # la catégorisation des cas d'usages suivant les activités des équipes cybersécurité, en suivant un découpage typique d'une organisation cybersécurité; | ||
# la catégorisation du cas d’usage en fonction des objectifs de sécurité qu’il cherche à traiter. Le NIST Cybersecurity Framework est ici utilisé ; | # la catégorisation du cas d’usage en fonction des objectifs de sécurité qu’il cherche à traiter. Le NIST Cybersecurity Framework est ici utilisé ; | ||
# le rapprochement du cas d’usage avec le traitement d’attaque du MITRE ATT&CK ou la mise en œuvre d’éléments de défense du MITRE D3FEND (non présenté dans ce document). | # le rapprochement du cas d’usage avec le traitement d’attaque du MITRE ATT&CK ou la mise en œuvre d’éléments de défense du MITRE D3FEND (non présenté dans ce document). | ||
| Ligne 80 : | Ligne 80 : | ||
La catégorisation des cas d’usages par rapport aux activités des équipes cybersécurité a permis de constituer 5 grandes catégories : | La catégorisation des cas d’usages par rapport aux activités des équipes cybersécurité a permis de constituer 5 grandes catégories : | ||
# La '''gestion des risques et de la conformité,''' incluant l’ensemble des activités de définition, traitement et gestion des risques et régulations applicables aux organisations ; | |||
# L’ '''évaluation de sécurité,''' souvent identifié au travail des « Red Teams », réalisant les activités d’audit, de tests d’intrusion, et de compromission de l’organisation ; | |||
# La '''sécurité applicative,''' intégrant les domaines de la gestion des identités et des accès, la mise sous protection des applications (Security by Design, SSDLC, SecDevOps, etc.) ; | |||
# La '''sécurité des infrastructures,''' intégrant la mise en œuvre des solutions de cybersécurité d’infrastructure (FW, IPS, EDR, Proxy, Annuaires, etc.) nécessaires à la sécurité en profondeur des systèmes d’information ; | |||
# Les '''activités de cyberdéfense,''' souvent identifié au travail des « Blue Teams », assurant la sécurité opérationnelle des Systèmes d’Information des organisations. | |||
==== Objectifs de sécurité ==== | ==== Objectifs de sécurité ==== | ||
Les objectifs de sécurité visent à déterminer les activités à mettre en œuvre afin de maîtriser les risques de cybersécurité au sein des organisations, ceux-ci sont découpés en 5 types selon le framework du NIST : | Les objectifs de sécurité visent à déterminer les activités à mettre en œuvre afin de maîtriser les risques de cybersécurité au sein des organisations, ceux-ci sont découpés en 5 types selon le framework du NIST : | ||
# '''IDENTIFIER''' ayant pour objectif l’identification, l’évaluation, et la mise en œuvre de l’organisation adaptée à la maîtrise du système d’information et au traitement des risques ; | |||
# '''PROTEGER''' ayant pour objectif de mettre en œuvre les activités nécessaires à la protection et au maintien en condition de sécurité des systèmes d’information ; | |||
# '''DETECTER''' ayant pour objectif d’identifier et de qualifier les incidents de cybersécurité ; | |||
# '''REPONDRE''' ayant pour objectif le traitement des incidents de cybersécurité : arrêt ou confinement de l’attaque, adaptation de la politique de sécurité ou de sa mise en œuvre ; | |||
# '''REPRISE''' ayant pour objectif de retourner à un état de fonctionnement normal suite à un incident de cybersécurité. | |||
Version du 27 octobre 2022 à 16:35
Catégorie : Groupe de travail Cycle : Cycle 2 Statut : En cours
Date de début : 2021/05/05
Date de fin : 2023/12/31
Description[modifier | modifier le wikicode]
Analyser les domaines de la cybersécurité où l’Intelligence Artificielle permet des avancées
Objectifs initiaux[modifier | modifier le wikicode]
- Cataloguer les usages potentiels de l’IA pour la cybersécurité
- Créer un environnement sandbox pour des cas d’usage de cybersécurité utilisant l’IA & cartographier les besoins
- Créer des parcours de formation à l’IA pour les professionnels de la cybersécurité à différents niveaux
- Identifier les startups spécialisées en solutions IA pour la cybersécurité et en réaliser une cartographie
- Outils / Usages offensifs dopés à l’IA
- Faire une étude de risque sur un cas d’usage réel anonymisé
- Faire des propositions pour la gouvernance de l’IA : certification, auditabilité, explicabilité
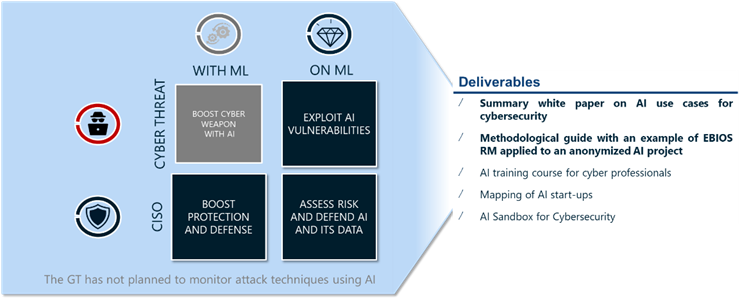
Livrables souhaités[modifier | modifier le wikicode]
- Livre blanc de synthèse sur des cas d’usage IA pour la cybersécurité
- Sandbox IA pour la cybersécurité : Plateforme IA avec outils et data sets
- Parcours de formations à l’IA pour les professionnels de la cyber
- Cartographie des startups IA
- Livre blanc sur les menaces spécifiques de l’IA
Synthèse des activités du GT[modifier | modifier le wikicode]
.png)
Les systèmes d’Intelligence Artificielle sont de plus en plus répandus dans les technologies de l’information modernes et affichent de nombreuses avancées dans les dernières années. En vue de préparer les prochaines générations d’applications et de système de défense contre les cyber menaces, le Campus Cyber, dans le cadre du Groupe de Travail Intelligence Artificielle et Cybersécurité, met en lumière les principaux usages de l’IA au bénéfice de la cybersécurité, les limites identifiées ainsi que les risques et principales mesures préconisées pour la sécurité de ces systèmes.
Quels acteurs impliqués dans les projets d'intelligence artificielle ?[modifier | modifier le wikicode]
Les projets d’Intelligence Artificielle impliquent de nombreux acteurs afin de valoriser la donnée et de répondre au cas d’usages préalablement identifié. L’identification des ressources clés est un enjeu majeur pour tout expert en cybersécurité au démarrage d’un projet, une description succincte des rôles et responsabilité permet d’identifier rapidement les parties prenantes. Les différentes phases d’un projet IA, dont le développement, la mise en production et le suivi d’une application IA fait appel à de nombreux acteurs, dont certains sont spécialistes de data science et d’autres ne le sont pas. Le schéma ci-dessous présente les quatre grandes familles d’acteurs identifiés :
- Les profils « métier », en charge du cas d’usage et de la validation de celui-ci par rapport aux objectifs de l’entreprise ;
- Les spécialistes de data science, en charge de la mise en œuvre des techniques d’Intelligence Artificielle pour répondre aux besoins identifiés par les « métier » ;
- Les profils IT, en charge du développement et de la mise en production des cas d’usages conçus par les spécialistes de la data science ;
- Les profils « risque », en charge du contrôle et du respect des pratiques mises en œuvre par rapport aux politiques internes et réglementations externes.
Notons que chaque entreprise peut avoir des noms un peu différents pour ces profils, voire découper différemment les rôles sur différents acteurs. Les descriptions suivantes sont donc à adapter à chaque cas : A mettre sous format graphique
- Profils « métier »
- Sponsor métier : l’entité ou la personne qui émet une expression de besoin pour un nouveau projet et qui est responsable de l’évaluation métier du projet en production.
- Citizen data scientist : il peut exécuter des processus de production de modèles avec des outils simples (no-code) pour démontrer/ explorer la valeur métier
- Analyste métier : il analyse les besoins métier et identifie les indicateurs de performance métier (KPI)
- Chef de projet IA : Il accompagne le projet dans l’expression fonctionnelle des besoins et pilote leur traduction en réalisation technique et leur exécution. Il encadre l’équipe projet.
- Spécialistes de data science
- Data analyst : Il réalise des études autour des données, et en restitue les conclusions
- Data engineer : il analyse les besoins en données, il définit les processus de collecte et monitoring selon les modes d’interaction (batch, fil de l’eau)
- Data scientist : c’est l’expert en data science, il conçoit le pipeline de construction du modèle et produit / sélectionne le modèle
- - Data visualizer : il élabore des visualisations des données et des résultats à destination des data scientists et des spécialistes métier
- Validateur de modèle : il s’assure de la validité du modèle et évalue ses conséquences non désirées éventuelles. Il assure une revue du modèle indépendante du développeur (data scientist)
- Profils IT
- Architecte solution : il propose une architecture de solution, comprenant les contraintes de cybersécurité
- Administrateur plateforme de production : il est responsable de la plateforme informatique où s’exécutent les modèles. Il assure le traitement des alertes et les reprises sur incidents lors des phases d’apprentissage et d’inférence
- Machine learning engineer : il intègre les pipelines machine learning dans des processus Machine Learning Operations(MLOps)
- Architecte de données : il conçoit les infrastructures et les solutions Data, il identifie les différentes sources de données
- Data manager : Il assure l’organisation et la gestion des données sur son domaine de responsabilité. Il agit comme un référent pour les données.
- Profils risque
- IA Security Champion : il apporte la déclinaison des politiques de sécurité pour le système IA
- Délégué à la Protection des Données (DPD) : il veille au respect de la réglementation sur la protection des données personnelle
- Responsable de la Sécurité des Systèmes d'Information (RSSI) : il décline les enjeux et besoins de sécurité pour le système IA. Il valide les niveaux de risques associés au système
Certains de ces profils sont transverses et interviennent sur de nombreux projets (sponsor métier, administrateur de plateforme de production, architecte données et profils risque) alors que d’autres sont dédiés à un projet et constituent une équipe projet. Les profils risque doivent donc intervenir aux côtés de profils IA dans des équipes projet mixtes.
Quels apports de l'intelligence artificielle pour la cybersécurité ?[modifier | modifier le wikicode]
L’Intelligence Artificielle, en tant que domaine scientifique, bénéficie de nombreuses avancées sur les dernières années, notamment grâce à la mise en commun de techniques, capacités et données permettant l’utilisation des approches statistiques du Machine Learning au détriment des approches déterministes des Systèmes Experts. Cette approche permet une généralisation et apporte des bénéfices lorsqu’un nombre significatif de données est mis en commun pour limiter les effets statistiques. De fait, les domaines de recherches en cybersécurité sont naturellement portés autours des axes suivants :
- L’identification et la localisation des informations de l’entreprise, en commençant pas la classification de ces informations, et l’application de politiques dynamiques ;
- La protection par l’analyse de signaux faibles et des comportements usuels, les systèmes à bas d’IA permettent de configurer les politiques et mécanismes de sécurité le plus efficacement possible ;
- La détection en analysant la moindre variation des comportements et des changements réalisés sur les infrastructures afin de construire dynamiquement les scénarios de détection ;
- La reprise via l’aide à la prise de décision, en ayant une connaissance fine du système d’information, permet d’établir la stratégie de réponse et de reprise associé à un incident de cybersécurité.
Fort des enjeux et des expérimentations réalisées dans de nombreux contextes, le Groupe de Travail a identifié un ensemble de cas d’usages cybersécurité pouvant être accéléré ou augmenté par l’utilisation d’Intelligence Artificielle. Pour cela, un canevas a été défini pour classifier et enrichir les cas d’usages :
Ce Framework de classification des cas d’usages est une initiative du Groupe de Travail : il est basé sur les guides et standards du domaine et se veut « pratique » pour catégoriser simplement des cas d’usages et favoriser l’identification de nouveaux cas. En complément de l’aide à l’organisation des connaissances, ce framework a été conçu pour faciliter le partage avec des entités internationales. Il est construit autour de trois axes :

- la catégorisation des cas d'usages suivant les activités des équipes cybersécurité, en suivant un découpage typique d'une organisation cybersécurité;
- la catégorisation du cas d’usage en fonction des objectifs de sécurité qu’il cherche à traiter. Le NIST Cybersecurity Framework est ici utilisé ;
- le rapprochement du cas d’usage avec le traitement d’attaque du MITRE ATT&CK ou la mise en œuvre d’éléments de défense du MITRE D3FEND (non présenté dans ce document).
Activités cybersécurité[modifier | modifier le wikicode]
La catégorisation des cas d’usages par rapport aux activités des équipes cybersécurité a permis de constituer 5 grandes catégories :
- La gestion des risques et de la conformité, incluant l’ensemble des activités de définition, traitement et gestion des risques et régulations applicables aux organisations ;
- L’ évaluation de sécurité, souvent identifié au travail des « Red Teams », réalisant les activités d’audit, de tests d’intrusion, et de compromission de l’organisation ;
- La sécurité applicative, intégrant les domaines de la gestion des identités et des accès, la mise sous protection des applications (Security by Design, SSDLC, SecDevOps, etc.) ;
- La sécurité des infrastructures, intégrant la mise en œuvre des solutions de cybersécurité d’infrastructure (FW, IPS, EDR, Proxy, Annuaires, etc.) nécessaires à la sécurité en profondeur des systèmes d’information ;
- Les activités de cyberdéfense, souvent identifié au travail des « Blue Teams », assurant la sécurité opérationnelle des Systèmes d’Information des organisations.
Objectifs de sécurité[modifier | modifier le wikicode]
Les objectifs de sécurité visent à déterminer les activités à mettre en œuvre afin de maîtriser les risques de cybersécurité au sein des organisations, ceux-ci sont découpés en 5 types selon le framework du NIST :
- IDENTIFIER ayant pour objectif l’identification, l’évaluation, et la mise en œuvre de l’organisation adaptée à la maîtrise du système d’information et au traitement des risques ;
- PROTEGER ayant pour objectif de mettre en œuvre les activités nécessaires à la protection et au maintien en condition de sécurité des systèmes d’information ;
- DETECTER ayant pour objectif d’identifier et de qualifier les incidents de cybersécurité ;
- REPONDRE ayant pour objectif le traitement des incidents de cybersécurité : arrêt ou confinement de l’attaque, adaptation de la politique de sécurité ou de sa mise en œuvre ;
- REPRISE ayant pour objectif de retourner à un état de fonctionnement normal suite à un incident de cybersécurité.
Journal de Bord[modifier | modifier le wikicode]
Texte à trous 1 Texte à trous 2 Texte à trous "
Communs
| Appliquer EBIOS RM à un système IA | Application du guide « méthodologie EBIOS RM » publié par l’ANSSI pour évaluer un système à base d’intelligence artificielle. |
| Cas d'usage IA et Cybersécurité | Le groupe de travail IA et cybersécurité a identifié plusieurs cas d'usages, listés ci-dessous. |
| Facilitateur en Intelligence Artificielle | Un facilitateur IA est un correspondant cyber disposant de connaissances pratiques en cybersécurité et en Intelligence Artificielle. |
| L'intelligence artificielle en cybersécurité | Identifie et analyse certains cas d'usage où l’Intelligence Artificielle permet des avancées pour la cybersécurité. |
| Référent sécurité en Intelligence Artificielle | Le référent cybersécurité pour les data scientists est intégré dans leur environnement de travail. Il est leur point de contact privilégié pour assurer concrètement la prise en compte de la cybersécurité dans les projets IA qu’ils développent. |
| Réglementation de l'IA | Synthèse de la règlemention européen dite « Artificial Intelligence Act ». |
| UC3 : Brand protection, fight against typo-squatting | Développement du Use Case pédagogique "UC 3 : Lutte contre le typosquatting" dans le cadre du GT IA et Cyber |
| UC5 : Machine Learning vs DDoS | Développement du Use Case pédagogique "Machine Learning vs Attaque DDoS" dans le cadre du GT IA et Cyber |
| UC7 : Suspicious security events detection | Développement du Use Case pédagogique "Suspicious security events detection" dans le cadre du GT IA et Cyber |
Cas d'usage
| Statut | ||
|---|---|---|
| Confidentiality Classification | ||
| Lutte contre le typo-squatting |